See the gallery of stimuli.
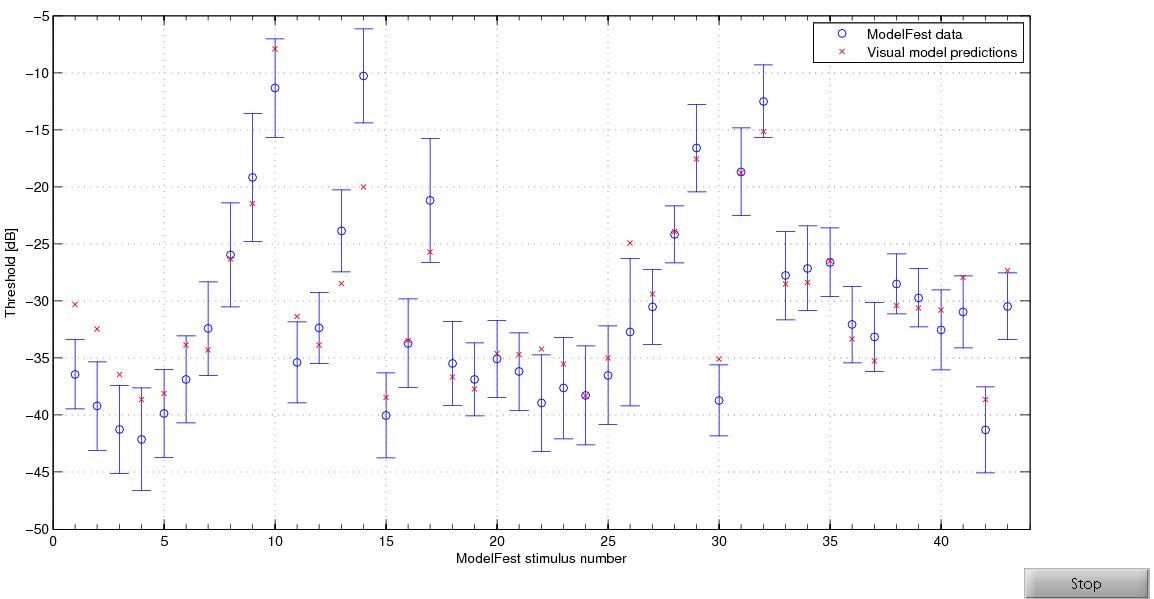
ModelFest is a standard data set created to calibrate and validate visual metrics. It contains 43 small detection targets at a uniform background of 30 cd/m2.
More about this dataset can be found in: Watson, A.B., and A.J. Ahumada Jr. "A standard model for foveal detection of spatial contrast". Journal of Vision 5, no. 9 (2005): link.
From the ModelFest website:
Since 1996, the annual meeting of the Optical Society of America has hosted a symposium entitled ModelFest. Conceived originally as a workshop in which those involved in the development of models of early human vision would demonstrate and discuss their work, it has more recently adopted as part of its program the establishment of a public, communal set of data. The purpose of the data set would be twofold: 1) to calibrate and 2) to test vision models. The data set was required to be large and varied enough to adequaltely serve both purposes. It was also hoped that the complete data set would be collected by a number of different labs, to enhance both the generality and accuracy of the data set. Thus the data set was constrained to be small enough that a large enough number of labs would volunteer. Acting through consensus, the informal group decided upon an inital effort (Phase 1) consisting of 44 two-dimensional monochromatic patterns confined to an area of approximately two by two degrees.
This is the Visual Difference Predictor for High Dynamic Range Images, C++ implementation from http://www.mpi-inf.mpg.de/resources/hdr/vdp/index.html, version 1.7
The metric is an extension of the VDP'93 metric that can better handle high dynamic range images. HDR-VDP includes, in addition to the VDP'93 feature set, a model of glare (intra-occular light scatter), photoreceptor response (single luminance channel) and the CSF that adapts locally to the pixel luminance.
The algorithm is described in: R. Mantiuk, S. Daly, K. Myszkowski, and H.P. Seidel. "Predicting visible differences in high dynamic range images: model and its calibration." In Human Vision and Electronic Imaging, 204-214, 2005.